
Research
メインメモリの高速化・低消費電力化とセキュリティ

コンピュータのメインメモリ(主記憶)は消費電力・性能の両面でボトルネックになっています。 消費電力面では 2007 年には既に Google のデータセンタのコンピュータの電力のうち 30% をメインメモリが占めており、近年のメモリ搭載量の増大からこれは更に悪化していると予測されます。 また性能面ではメインメモリに使われる DRAM のアクセス遅延は 20 年以上にわたり改善していません。
これらの問題を解決するため、Approxiamte Memory、不揮発性メモリ、Process in Memory (PIM) という三つの新しいメモリ方式の利用法・制御法、また従来方式のメモリをより効率よく使う方法を研究しています。 Approximate Memory は、DRAM 内部の電気的操作を適宜「さぼる」ことで高速・低消費電力を実現します。 不揮発性メモリはデータ保持の物理的な原理が DRAM とは全く異なるメモリで、電流を流さなくてもデータが消えないなどの利点があります。 最後の PIM はメモリ内部に計算回路を持ったり特殊な電気的操作をしたりすることで、 データを CPU に転送せずにメモリ内で計算を行う技術です。 これらの新しいメモリ方式を使ってその上で動くソフトウェアに最大限の恩恵を与えるにはどうすればいいか、が一つの大きな研究テーマです。
新しいメモリ方式ではそのセキュリティも課題で、今後研究を進める予定です。 例えば Approximate Memory では、電気的に不安定になるため RowHammer と呼ばれる攻撃に弱いと予想され、またさぼり具合の制御部分が攻撃されるとコンピュータが異常動作するという問題があります。 新しいメモリ方式の利点とセキュリティをどう両立するかは世界的にも議論が不十分な未知のチャレンジです。
主な研究成果:
- The Granularity Gap Problem: A Hurdle for Applying Approximate Memory to Complex Data Layout, ACM/SPEC ICPE, 2021
- Reliable Reverse Engineering of Intel DRAM Addressing Using Performance Counters, IEEE MASCOTS, 2020
- A Lightweight Method to Evaluate Effect of Approximate Memory with Hardware Performance Monitors, IEICE Trans. Inf. & Syst, 2019
- Towards Write-back Aware Software Emulator for Non-Volatile Memory, IEEE NVMSA, 2017
計算効率を高めるためのシステムソフトウェア
システムソフトウェアとは、オペレーティングシステムや仮想マシンのような、 コンピュータを制御しきちんと動かすためのソフトウェアのことを言います(これに対しユーザの直接の目的を実現するソフトウェアはアプリケーションソフトウェアやアプリケーションと呼びます)。 システムソフトウェアには計算リソースの分配、保護、抽象化など様々な目的がありますが、当研究室では特にシステムソフトウェアによってアプリケーションの計算効率を高める研究をしています。
アプリケーションが単一のマシン上の単一の CPU で実行されていた時代から大きく進化し、 現代では複数の CPU や複数のマシンが協調し計算を行うことが日常的です。 このような複雑なコンピュータシステム上でのアプリケーションの効率化は、アプリケーションプログラマが自ら行うには難しい仕事です。 これにはコンピュータシステムシステムの深い知識が要求され、またその知識はアプリケーションで行いたい計算の本質とは関係ない場合も多いからです。 そこでシステムソフトウェアの助けによるアプリケーションの自動的な効率化が必要と信じ研究を進めています。
主な研究成果:
- An Empirical Study of Method Chaining in Java, MSR, 2020
- Diagnosing Performance Fluctuations of High-throughput Software for Multi-core CPUs, IPDPSW, 2018
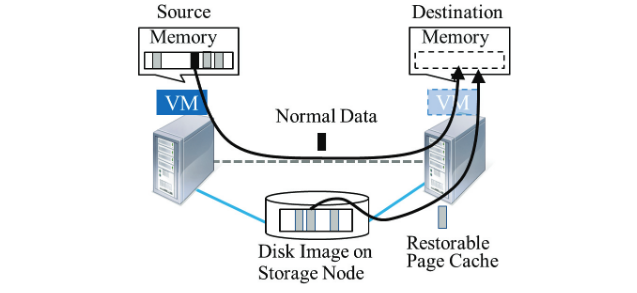
- Fast Live Migration for IO-Intensive VMs with Parallel and Adaptive Transfer of Page Cache via SAN, IEICE Trans. Inf. & Syst., 2016
- Optimizing Distributed Actor Systems for Dynamic Interactive Services, EuroSys, 2016
FPGA による効率的な計算
FPGA (Field Programmable Gate Array) とは、回路要素を自由に組み替えて目的の計算を達成するデバイスです。 FPGA はそのカスタマイズ性、消費電力あたりの計算能力の高さ、実現可能な並列度の高さが特徴です。 これらの利点から FPGA は様々な分野への応用が期待されており、当研究室でも FPGA による効率的な計算の実現に向けて研究しています。
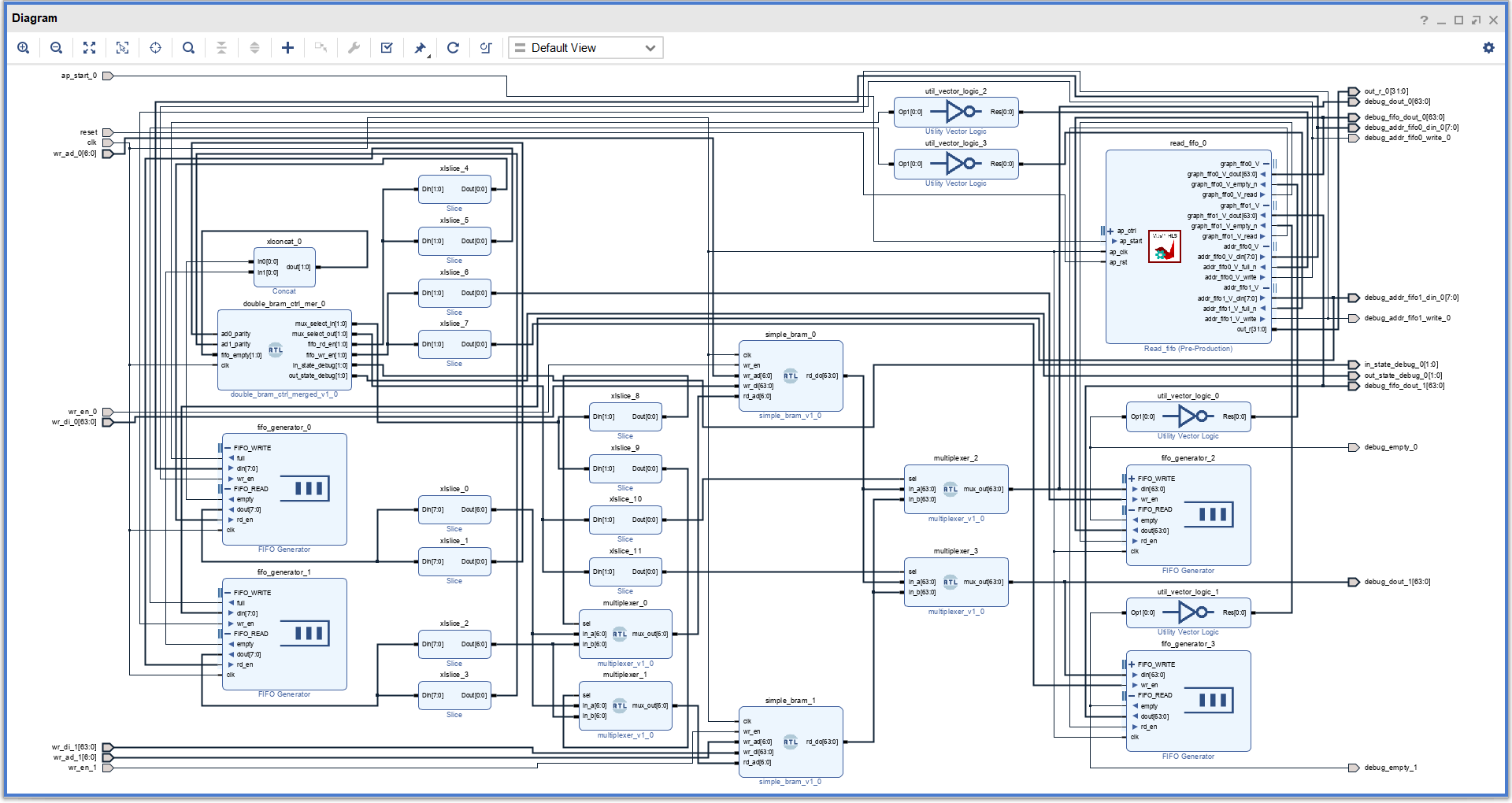
例えば下に示す研究成果では、自動車の走行抵抗係数(空気抵抗やタイヤと路面の摩擦を表す係数)を推定するニューラルネットワークを FPGA で実装し、2.1 W 以下の消費電力で動作可能にしました。 これはスマホの充電に必要な電力よりも小さく、走行中の自動車に載せて実行可能な消費電力です。 また FPGA 上のグラフ処理において必要なグラフノードのデータをなるべく並列に読み出せるような回路設計・データ配置の研究もしています。
主な研究成果:
- ニューラルネットワークを用いた走行抵抗係数推定とその FPGA による低消費電力実装, 自動車技術会論文集, 2022
- FPGA グラフ処理のための頂点アクセス並列化によるプログラマビリティの高い HLS フレームワーク, HotSPA, 2022